Back in 22 there was a bit of a flareup on twitter over a paper with the very spicy title
Principal Component Analyses (PCA)-based findings in population genetic studies are highly biased and must be reevaluated
According to the abstract, there are tens (or even hundreds) of thousands of papers affected by this high bias, and
PCA results may not be reliable, robust, or replicable as the field assumes.
I would love to live in a world where you could get funding to re-evaluated a hundred thousand articles. Maybe if you say that you’ll do it by AI?
I skimmed the paper then and honestly I don’t care to re-read it. I’m just providing some context for this theorem I know of.
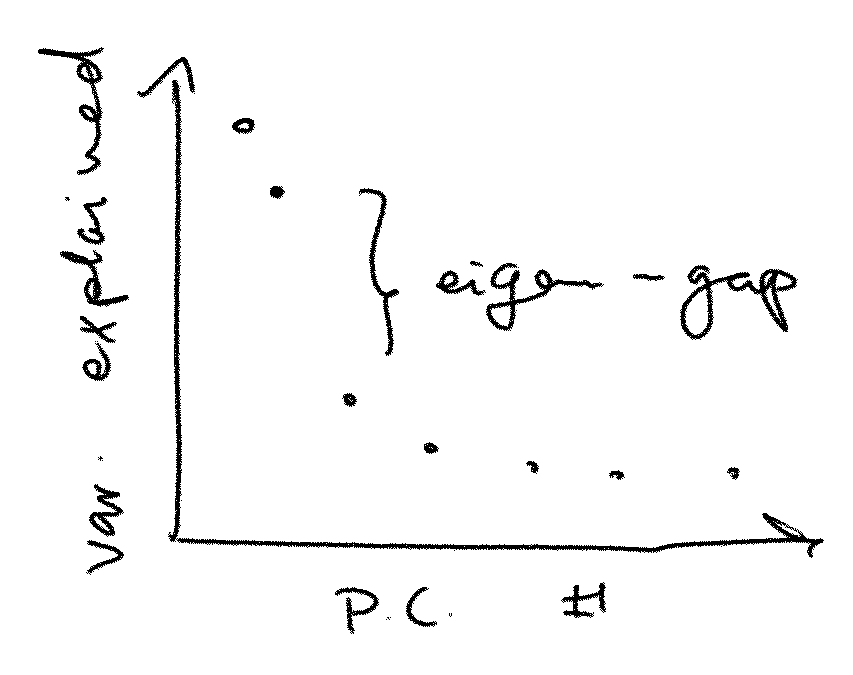
It is certainly true that if you take two random samples from the same population and do a PCA on both of them, you’re not likely to get two exactly identical sets of principal component vectors. Or if you take a single sample from a population you’re not likely to get the exact true population principal components back. However there is a theorem that if the “eigengap” (described below) is large enough, the top principal components are likely to span the right space.
PCA is an eigenvalue decomposition of a symmetric matrix (the covariance matrix of your data). Suppose for simplicity we’re working in two dimensions and let our covariance matrix be a symmetric matrix with the eigenvalues . In PCA terms these correspond to the “variance explained” values of your scree plot. The eigengap between these two eigenvalues is . Now let be the corresponding eigenvectors to and . These are the true population principal components.
We do a random sample and get , a perturbation of (still symmetric), meaning it’s plus some noise. We don’t know how much noise is in there. Suppose and are the eigenvectors of : how reliable/robust/replicable is an inference based on in place of ?
The DK theorem informs us that if is the angle between and we have
with the Frobenius norm.
In other words, the angle between our observed vector and the hidden true vector is smaller than the scale of the added noise divided by the size of the eigengap. Multiplied by an annoying constant. We get a vector close to (ie with small angle to) the truth if we have little noise or a large eigengap (or, God willing, both).
This extends to several dimensions where instead of looking at the angle between two vectors we look at the angle between subspaces. The space spanned by the top principal components is robust if there is a large gap between the -th and the th eigenvalues.
I don’t believe that a hundred thousand articles are biased, in the technical sense, from use of PCA, but I 100% believe that many many articles have large noise and small eigengaps. But you can’t really blame PCA for noisy data.
Two nice blog posts on this sort of thing:
Original paper of D and K (did not read):
There is a paper called A useful variant of the Davis–Kahan theorem for statisticians, which has a promising title.
On measuring the angle between subspaces:
this file last touched 2024.05.28